if metrics["parity_diff"] > POLICY["fairness"]["parity_diff_max"]:
violations.append("fairness")
if metrics["accuracy"] < POLICY["performance"]["accuracy_min"]:
violations.append("performance")
if flags.get("pii_detected") and not POLICY["privacy"]["pii_allowed"]:
violations.append("privacy")
if POLICY["robustness"]["adv_eval_required"] and not flags.get("adv_test_passed"):
violations.append("robustness")
return violations
Risk Tiering Model
| Tier | Criteria | Examples | Required Controls |
|---|---|---|---|
| Low | Internal optimization, low impact | Cache prediction | Basic logging |
| Medium | User-facing, limited impact | Recommendation ranker | Standard metrics + fairness scan |
| High | High stakes decisions (credit, hiring) | Credit scoring | Full documentation, external audit, explainability report |
| Critical | Safety, legal, or life-impacting | Medical triage model | Third-party assessment, heightened monitoring, incident SLA |

Risk Register Template (Excerpt)

Figure: Prompt workspace – system message, examples, and completion preview.
Risk ID: R-023
Description: Potential gender bias in loan approval model
Likelihood: Medium
Impact: High
Mitigation: Reweight training set, apply threshold optimizer
Owner: Fairness Lead
Status: Mitigation in progress
Review Cycle: Monthly
Model Documentation Artifacts
| Artifact | Purpose | Frequency | Owner |
|---|---|---|---|
| Model Card | Summary, metrics, limitations | Each major version | Model Owner |
| Datasheet | Data provenance & quality | Dataset creation/update | Data Steward |
| Risk Summary | Consolidated risk posture | Quarterly | Governance Team |
| Fairness Report | Bias evaluation & mitigations | Each retrain | Fairness Lead |
| Drift Log | Historical drift events | Continuous | MLOps Engineer |
Lineage & Traceability

Figure: Configuration and management dashboard with status overview.
import json, hashlib

def lineage_record(files, metadata):
```sql
h = hashlib.sha256()
for f in files:
with open(f,'rb') as fh: h.update(fh.read())
record = {"hash": h.hexdigest(), **metadata}
open("lineage.json","w").write(json.dumps(record, indent=2))
## Approval Workflow (State Machine)
| State | Trigger | Next State | Action |
|-------|---------|-----------|--------|
| Draft | Metrics logged | Review Pending | Freeze artifacts |
| Review Pending | Governance board scheduled | In Review | Collect signatures |
| In Review | All approvals collected | Approved | Tag version |
| In Review | Rejection logged | Revision Required | Address violations |
| Approved | Deployment request | Deployed | Emit audit event |
## Audit Logging & Queries
### KQL Sample (Deployment Approvals)
```kql
CustomEvents
| where name == "model_approval"
| project timestamp, customDimensions.ModelName, customDimensions.Version, customDimensions.Status, customDimensions.Approvers
Continuous Compliance Monitoring
- Scheduled policy enforcement job.
- Diff detection: environment, dependency license drift.
- Unmonitored fairness subgroup alert.
- SLA breach escalation (latency, parity, accuracy).
KPI Catalog
| KPI | Definition | Target |
|---|---|---|
| Approval Cycle Time | Draft → Approved duration | < 5 business days |
| Policy Violation Rate | Violations / evaluation cycles | < 10% |
| Documentation Freshness | Days since last artifact update | < 30 days |
| Audit Query Latency | Time to retrieve lineage record | < 3s |
| Exception Reopen Rate | Reopened after closure | < 5% |
Exception Handling Playbook
- Identify violation type (fairness, privacy, robustness).
- Classify severity (low/medium/high/critical).
- Apply mitigation (data fix, threshold recalibration, shielding feature removal).
- Re-run gated tests; if pass, resume workflow.
- Document outcome & root cause in risk register.
Security & Privacy Controls
| Control | Implementation | Verification |
|---|---|---|
| Encryption at Rest | Storage account + Key Vault keys | Azure Policy audit |
| Differential Privacy (DP) | Laplace noise for aggregate stats | DP test harness |
| Access Segregation | Separate RBAC roles | Role review quarterly |
| Secret Management | Key Vault references | Rotation log |
| Inferential Risk Checks | k-anonymity / l-diversity evaluation | Data profiling report |
Explainability & Accountability
Integrate SHAP/LIME outputs into model card; require rationale for excluded features; maintain decision trace for recourse analysis.

Fairness Mitigation Policy (Excerpt)
fairness_policy:
triggers:
```yaml
parity_diff: 0.08
adverse_impact_ratio: 0.80```
actions:
```text
- reweight_training
- apply_threshold_optimizer
- subgroup_feature_audit```
escalation:
```yaml
owner: fairness_lead
review_window_days: 7
## Maturity Model (Governance Capability)
| Level | Characteristics | Focus |
|-------|-----------------|-------|
| 1 Ad-hoc | Manual reviews, undocumented | Establish artifacts |
| 2 Defined | Policies documented, partial enforcement | Introduce gating tests |
| 3 Integrated | Automated gates + audit logs | Expand risk monitoring |
| 4 Managed | Metrics & SLA tracked | Optimize cycle time |
| 5 Optimizing | Predictive risk scoring | Adaptive policies |
| 6 Autonomous | Self-healing compliance (auto remediation) | Strategic oversight dashboards |
## Metrics & Dashboards
Core panels: policy violations trend, approval cycle, fairness parity per subgroup, documentation freshness, top risk categories.
## Best Practices
- Codify policies early; avoid retrofitting controls.
- Centralize model artifacts; enforce version immutability.
- Couple fairness + performance gating to avoid trade-off blind spots.
- Automate lineage capture at build time.
- Record exceptions with structured reason codes.
- Provide transparent recourse instructions for affected users (if applicable).
## Anti-Patterns
| Anti-Pattern | Risk |
|--------------|------|
| Manual sign-offs in email | Lost audit trail |
| One-time fairness check | Drift-induced bias |
| Hidden feature transformations | Unexplained decisions |
| Overly strict thresholds blocking innovation | Stalled delivery |
| Unversioned documentation | Inconsistent narratives |
## FAQs
| Question | Answer |
|----------|--------|
| How to align with EU AI Act risk tiers? | Map internal risk classification to Act levels; apply supplementary documentation for high-risk systems. |
| Do all models need full governance? | Scope by risk tier; low-tier gets lightweight controls. |
| How often to refresh model card? | Every material version (perf or feature change). |
| What triggers exception workflow? | Policy violation, missing artifact, failing gate. |
| How to measure governance ROI? | Reduced cycle time, lower incident rate, audit readiness metrics. |

## References
- EU AI Act Draft Text
- NIST AI Risk Management Framework
- ISO/IEC 23894 Guidance
- GDPR Articles (Data Minimization & Explainability)
- Azure ML Responsible AI Documentation
## Next Steps
- Implement policy as code module in CI.
- Add approval event emission to telemetry.
- Integrate fairness & robustness reports automatically into model card generation.
## Technical Control Library (Overview)
| Control ID | Category | Description | Enforcement Mechanism | Evidence Artifact |
|------------|----------|-------------|-----------------------|-------------------|
| CTRL-FR-01 | Fairness | Parity diff threshold gate | Pytest + metrics JSON | fairness_report.json |
| CTRL-PV-03 | Privacy | PII scan pre-train | NLP entity detection + regex | pii_scan_log.txt |
| CTRL-RB-02 | Robustness | Adversarial perturbation test set | FGSM / PGD script | adv_eval_metrics.csv |
| CTRL-TR-05 | Transparency | Model card generation | Template render script | model_card.md |
| CTRL-LN-04 | Lineage | Artifact hash + source commit capture | Build hook script | lineage.json |
| CTRL-SC-07 | Security | Dependency vulnerability scan | SCA tool (e.g., Trivy) | vulns_report.json |
| CTRL-AU-08 | Audit | Approval event logging | CI workflow step | audit_events.log |
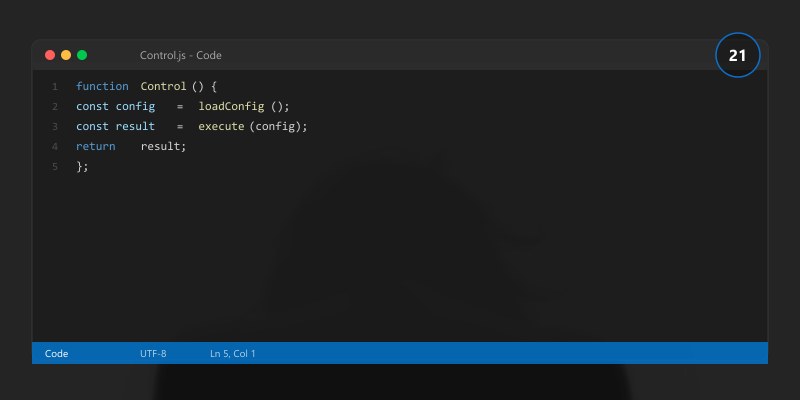
## Control Implementation Example (Fairness Gate)
```python
def fairness_gate(metrics, threshold=0.08):
```text
return metrics.get("parity_diff", 1.0) <= threshold
def run_fairness_control(metrics):
passed = fairness_gate(metrics)
with open("fairness_report.json","w") as f:
json.dump({"passed": passed, "metrics": metrics}, f, indent=2)
if not passed:
raise SystemExit("Fairness control failed: parity_diff exceeds threshold")
## CI Integration (GitHub Actions Snippet)
```yaml
jobs:
governance-checks:
```python
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Install deps
run: pip install -r requirements.txt
- name: Run policy enforcement
run: python scripts/enforce_policy.py --metrics metrics/latest.json --flags flags.json
- name: Run fairness gate
run: python scripts/fairness_gate.py --metrics metrics/latest.json
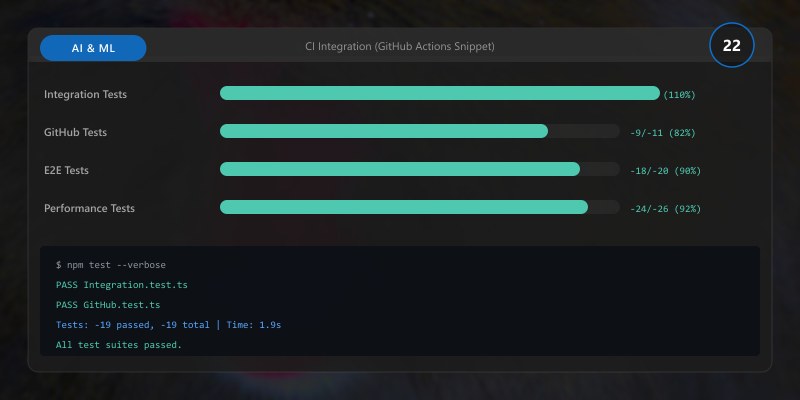
- name: Upload artifacts
uses: actions/upload-artifact@v3
with:
name: governance-artifacts
path: |
fairness_report.json
lineage.json
model_card.md
## Azure DevOps Extension (Policy Stage)
```yaml
stages:
- stage: Governance
```python
jobs:
- job: PolicyChecks
steps:
- task: AzureCLI@2
inputs:
azureSubscription: 'ml-governance'
scriptType: bash
scriptLocation: inlineScript
inlineScript: |
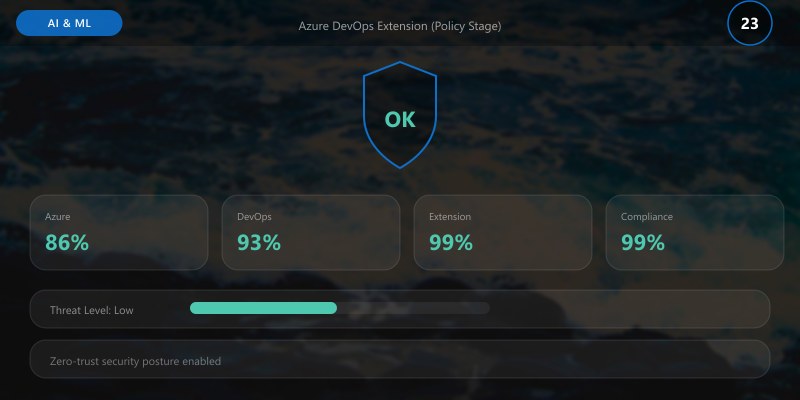
python scripts/policy_gate.py --config governance/policy.yml --metrics artifacts/metrics.json
python scripts/risk_update.py --risklog governance/risk_register.csv
## Risk Scoring Formula
```python
def risk_score(likelihood, impact, exposure, detectability):
```text
# All inputs normalized 1..5
return (likelihood * impact * exposure) / (detectability + 0.5)
def score_to_level(score):
if score < 15: return "Low"
if score < 35: return "Medium"
if score < 60: return "High"
return "Critical"
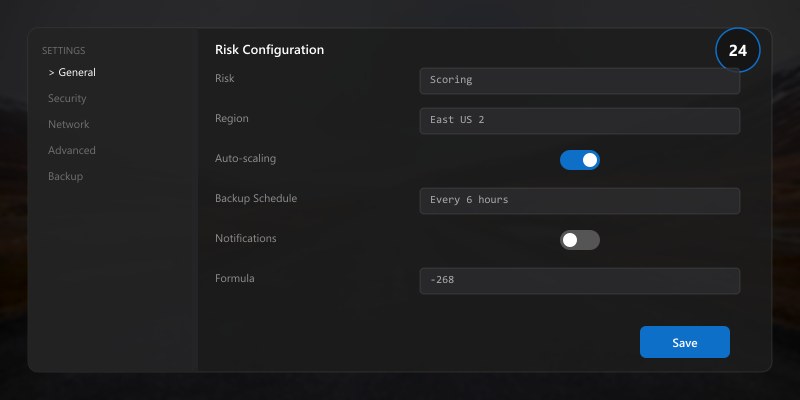
Use risk score to prioritize mitigation backlog and escalation routing.
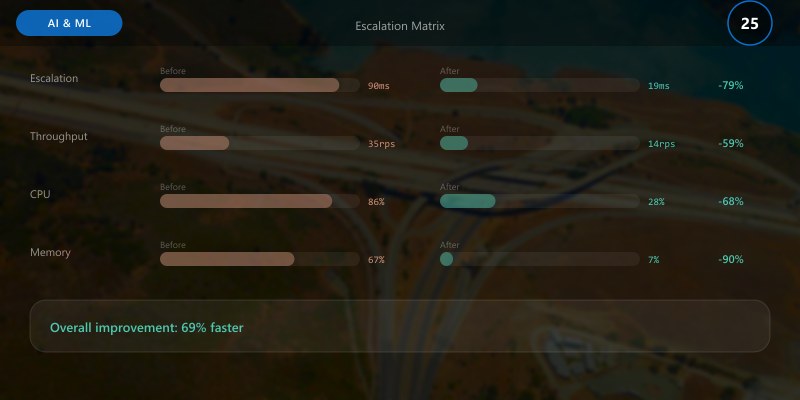
## Escalation Matrix
| Severity | Escalation Target | SLA Response | Communication Channel | Examples |
|----------|-------------------|--------------|----------------------|----------|
| Low | Model Owner | 5 business days | Ticket system | Minor doc stale |
| Medium | Governance Team | 2 business days | Email + dashboard | Threshold near breach |
| High | Risk Committee | 24h | Chat + incident board | Fairness violation |
| Critical | Executive Oversight | 4h | War room call | Privacy breach, legal risk |
## Automation Hooks
- Pre-commit: Lint governance YAML for schema validity.
- Pre-push: Verify model card regenerated when metrics changed.
- CI post-train: Emit lineage + fairness artifacts.
- Deployment: Tag release with compliance status.
- Post-deployment: Schedule monitoring job registration.
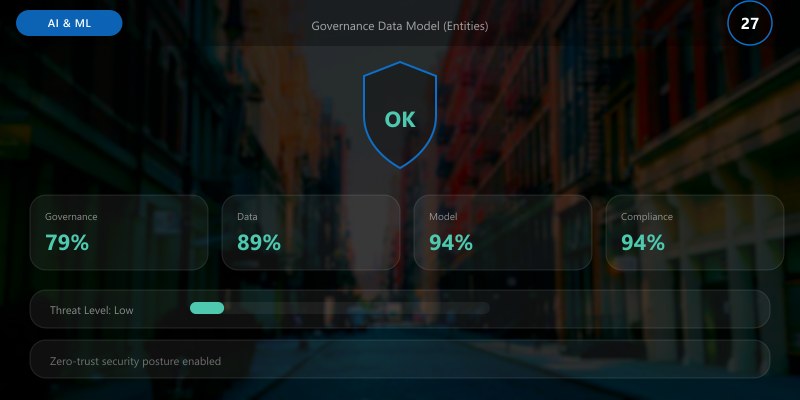
## Governance Data Model (Entities)
| Entity | Key Fields | Relationship |
|--------|-----------|--------------|
| ModelVersion | id, hash, metrics_ref | 1:N with ApprovalEvent |
| ApprovalEvent | id, model_version_id, approvers, status | Links stakeholders |
| PolicyViolation | id, model_version_id, type, severity | Drives exceptions |
| RiskItem | id, category, score, mitigation | Aggregates posture |
| Artifact | id, type, path, version | Traceable evidence |
## Bicep: Governance Storage Resources
```bicep
resource govStorage 'Microsoft.Storage/storageAccounts@2022-09-01' = {
name: 'govartifacts${uniqueString(resourceGroup().id)}'
location: resourceGroup().location
sku: { name: 'Standard_LRS' }
kind: 'StorageV2'
properties: {
```yaml
allowBlobPublicAccess: false
minimumTlsVersion: 'TLS1_2'```
}
}
resource govContainer 'Microsoft.Storage/storageAccounts/blobServices/containers@2022-09-01' = {
name: '${govStorage.name}/default/governance-artifacts'
properties: {
```yaml
publicAccess: 'None'```
}
}
Terraform: Key Vault for Secrets

Figure: Azure Key Vault blade – secrets list with expiry dates and access policies.
resource "azurerm_key_vault" "gov" {
name = "gov-kv"
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
tenant_id = data.azurerm_client_config.current.tenant_id
sku_name = "standard"
purge_protection_enabled = true
soft_delete_retention_days = 30
}
Audit Query Library (KQL)

Figure: Component library – reusable controls with custom input/output properties.
CustomEvents
| where name in ("policy_violation", "model_approval", "lineage_capture")
| project timestamp, name, customDimensions
| order by timestamp desc
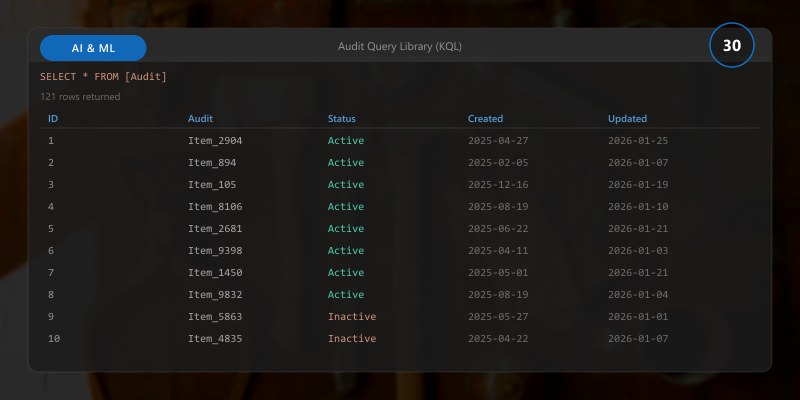
CustomMetrics
| where MetricName startswith "fairness_" or MetricName startswith "perf_"
| summarize avg(MetricValue) by MetricName, bin(TimeGenerated, 1d)
Governance Dashboard Panels
| Panel | Metric | Visualization | Decision Support |
|---|---|---|---|
| Violations Trend | Count by type | Stacked area | Identify systemic issues |
| Approval SLA | Avg cycle time | Line chart | Process optimization |
| Risk Heatmap | Risk score categories | Heat matrix | Prioritize mitigation |
| Fairness Stability | Parity diff timeline | Multi-line | Detect creeping bias |
| Documentation Freshness | Age distribution | Histogram | Prompt updates |
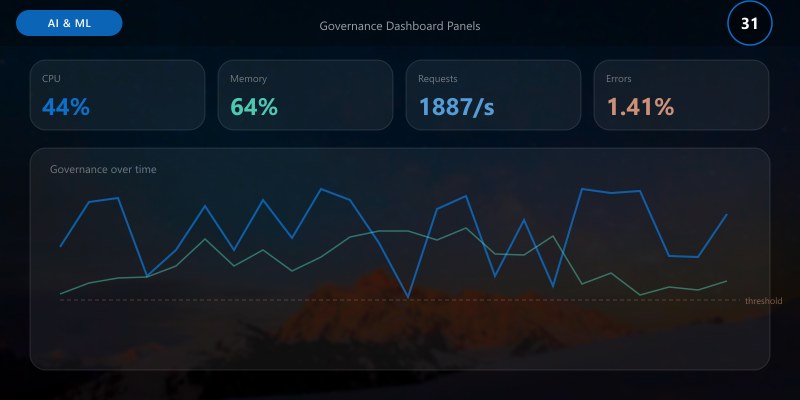
Predictive Risk Modeling
Train classifier on historical violation patterns (features: model complexity, data volatility, past incidents) to predict probability of future high-severity breach; use to pre-allocate review attention.

License Compliance Scan

Figure: Azure Policy compliance dashboard – initiative scores and remediation tasks.
import pkg_resources, json
ALLOWED = {"MIT","Apache-2.0","BSD"}
violations = []
for dist in pkg_resources.working_set:
```text
meta = getattr(dist,'_provider',None)
license = getattr(meta,'license',"Unknown") if meta else "Unknown"
if license not in ALLOWED:
violations.append({"package": dist.project_name, "license": license})```
open('license_scan.json','w').write(json.dumps(violations, indent=2))
> **Architecture Overview:** ## Data Privacy Impact Assessment (DPIA) Checklist
def composite_governance_risk(categories):
# categories = {name: {"risk":0.4,"detectability":0.7,"weight":0.25}, ...}
total = 0.0
for c,data in categories.items():
```text
residual = data["risk"] * (1 - data["detectability"]) * data.get("weight",0.2)
total += residual```
return round(total,4)
Governance Simulation (Policy Impact)

Figure: Azure Policy compliance dashboard – initiative scores and remediation tasks.
def simulate_threshold_change(current_metrics, new_thresholds):
impacts = {}
for k,v in new_thresholds.items():
```text
metric_val = current_metrics.get(k)
if metric_val is None: continue
impacts[k] = {
"current": metric_val,
"threshold": v,
"status": "pass" if metric_val <= v else "fail"
}```
return impacts
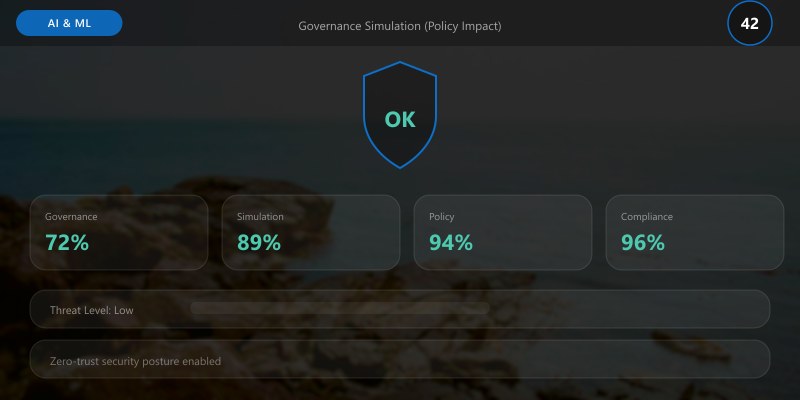
Enable scenario analysis before tightening fairness or privacy thresholds that could create false failure overhead.
Governance Knowledge Graph (Conceptual)
Nodes: ModelVersion, Dataset, Policy, Violation, ApprovalEvent, RiskItem. Edges: (ModelVersion)-[USES]->(Dataset), (ModelVersion)-[SUBJECT_TO]->(Policy), (Policy)-[TRIGGERS]->(Violation), (Violation)-[RESOLVED_BY]->(ApprovalEvent). Query examples: "Which high-risk models had fairness violations in last quarter without mitigation update?"
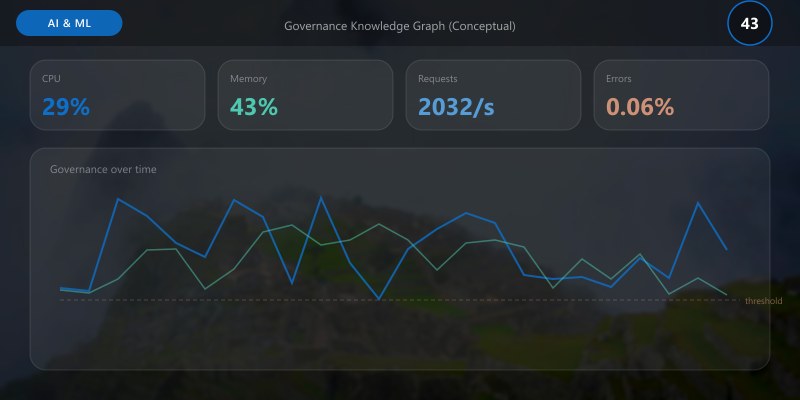
SPARQL-like Query Pseudo

Figure: SSMS query editor – execution plan, results grid, and query statistics.
SELECT model, violationDate
WHERE model.riskLevel = 'High'
AND violation.type = 'Fairness'
AND violationDate > NOW()-90d
AND NOT EXISTS ( mitigationUpdate AFTER violationDate )
Advanced KPI Formulas
| KPI | Formula | Purpose |
|---|---|---|
| Automation Effectiveness | AutomatedPassed / (AutomatedPassed + ManualPassed) | Shows control shift to automation |
| False Block Rate | (FalseViolations / TotalViolations) | Measures over-stringency |
| Mitigation Velocity | Avg(T_violation_to_fix) | Remediation speed |
| Governance Coverage | ImplementedControls / PlannedControls | Roadmap progress |
| Residual Risk Trend | Slope(residual risk over time) | Directional posture |
Residual Risk Trend Calculation

Figure: Configuration and management dashboard with status overview.
def residual_risk_slope(risks):
import numpy as np
ys = np.array(risks)
xs = np.arange(len(ys))
slope = np.polyfit(xs, ys, 1)[0]
return slope

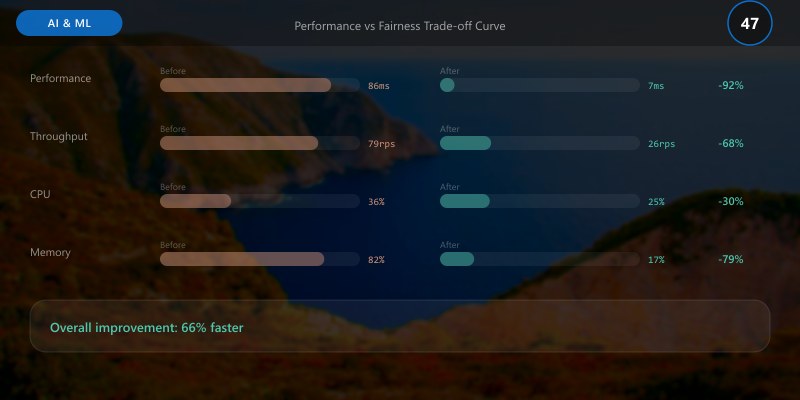
Performance vs Fairness Trade-off Curve
Store points (accuracy, parity_diff). Use convex hull to identify Pareto frontier representing optimal balance.
def pareto_frontier(points):
# points: list of (accuracy, parity_diff)
frontier = []
for p in sorted(points, key=lambda x: -x[0]):
```text
if not frontier or p[1] <= frontier[-1][1]:
frontier.append(p)```
return frontier
Model Card Auto-Generation Snippet

Figure: Azure ML Studio – training pipeline, metrics, and model registry.
import yaml, datetime
def generate_model_card(meta, metrics, fairness, risk):
card = {
```text
"model": meta,
"generated_at": datetime.datetime.utcnow().isoformat(),
"metrics": metrics,
"fairness": fairness,
"risk": risk,
"limitations": meta.get("limitations",[]),
"ethical_considerations": meta.get("ethical",[])```
}

open("model_card.md","w").write("---\n"+yaml.dump(card)+"---\n")
Ethical Review Checklist
| Area | Question | Status |
|---|---|---|
| Human Oversight | Is override mechanism documented? | Pending |
| Avoidance of Harm | Are harmful output filters active? | Pending |
| Inclusive Design | Were diverse test cohorts used? | Pending |
| Recourse | Are user appeal channels defined? | Pending |
| Transparency | Can user request explanation? | Pending |

End-to-End Compliance Pipeline (ASCII)

Figure: Azure DevOps pipeline – stages, deployment gates, and artifact publishing.
Commit → Train → Metrics Log → Governance Checks → Policy Gate → Approval Board (High-Risk) → Artifact Publish → Deploy → Continuous Monitoring → Drift/Fairness Alerts → Exception Workflow → Risk Register Update → Periodic Audit
Continuous Improvement Loop
- Measure governance KPIs monthly.
- Identify bottlenecks (e.g., slow approval cycle) via dashboard.
- Propose automation or threshold tuning.
- Pilot change in staging; monitor false block rate.
- Rollout globally; update maturity level assessment.
Quantifying Governance Value
Combine reduced incident cost + avoided regulatory penalty probability * estimated penalty amount + efficiency time savings monetized by average engineer cost rate.
def governance_value(incident_reduction, avoided_penalty_prob, penalty_amount, hours_saved, hourly_rate):
return (incident_reduction + avoided_penalty_prob * penalty_amount + hours_saved * hourly_rate)
Closing Statement
Governance maturity is a strategic asset: systematically reducing risk surface while accelerating trustworthy deployment velocity and preserving stakeholder confidence.
Azure Monitor Governance Queries (KQL)

Figure: Azure Monitor Logs – KQL query results with time-series visualization.
CustomEvents
| where name == "policy_violation"
| summarize count() by tostring(customDimensions.type), bin(timestamp, 1d)
CustomEvents
| where name == "model_approval"
| summarize avg(minute(diffminutes(tolong(customDimensions.approvalStart), tolong(customDimensions.approvalEnd)))) by bin(timestamp,1d)
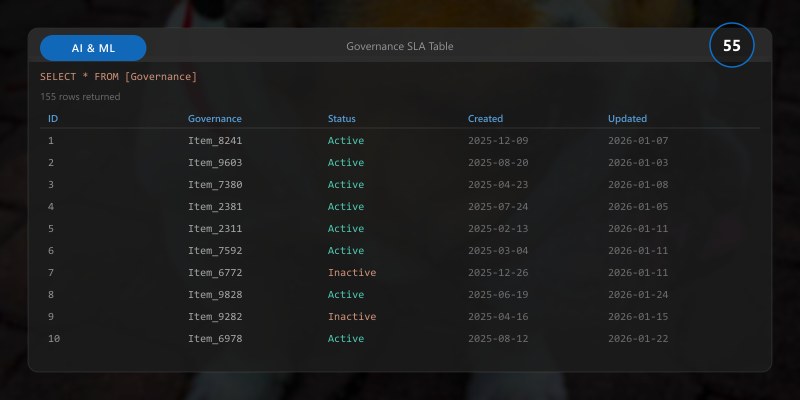
Governance SLA Table
| SLA | Target | Breach Condition | Escalation |
|---|---|---|---|
| Approval Cycle | < 5 days | > 5 days open | Governance Team |
| Fairness Violation Fix | < 7 days | > 7 days unresolved | Risk Committee |
| Privacy Incident Containment | < 4h | > 4h containment | Exec Oversight |
| Lineage Availability | 99% | Missing artifact lookup | Platform Team |
Rapid Remediation Scripts

Figure: Swagger UI – API endpoints with HTTP methods, schemas, and try-it-out.
def rollback_model(endpoint, previous_version):
# pseudo-call
print(f"Routing traffic back to version {previous_version}")
def reweight_dataset(df, sensitive_attr):
import pandas as pd
weights = df.groupby(sensitive_attr).size().to_dict()
df['sample_weight'] = df[sensitive_attr].map(lambda v: 1/weights[v])
return df
Governance Heatmap Generation

Figure: Azure Policy compliance dashboard – initiative scores and remediation tasks.
def governance_heatmap(risks):
# risks: list of {"model":"x","fairness":0.2,"privacy":0.1,"robustness":0.3}
import pandas as pd
df = pd.DataFrame(risks)
df.to_csv('governance_heatmap.csv', index=False)
Additional References
- NIST SP 1270 Guidance
- ISO 27001 (Security alignment)
- SOC 2 Trust Principles
- Open Policy Agent (Policy enforcement tooling)

Architecture Decision and Tradeoffs
When designing AI/ML solutions with Azure AI Services, consider these key architectural trade-offs:
| Approach | Best For | Tradeoff |
|---|---|---|
| Managed / platform service | Rapid delivery, reduced ops burden | Less customisation, potential vendor lock-in |
| Custom / self-hosted | Full control, advanced tuning | Higher operational overhead and cost |
Recommendation: Start with the managed approach for most workloads and move to custom only when specific requirements demand it.
Validation and Versioning
- Last validated: April 2026
- Validate examples against your tenant, region, and SKU constraints before production rollout.
- Keep module, CLI, and SDK versions pinned in automation pipelines and review quarterly.
Security and Governance Considerations
- Apply least-privilege access using RBAC roles and just-in-time elevation for admin tasks.
- Store secrets in managed secret stores and avoid embedding credentials in scripts or source files.
- Enable audit logging, data protection policies, and periodic access reviews for regulated workloads.
Cost and Performance Notes
- Define budgets and alerts, then monitor usage and cost trends continuously after go-live.
- Baseline performance with synthetic and real-user checks before and after major changes.
- Scale resources with measured thresholds and revisit sizing after usage pattern changes.
Official Microsoft References
- https://learn.microsoft.com/azure/ai-services/
- https://learn.microsoft.com/azure/machine-learning/
- https://learn.microsoft.com/azure/ai-foundry/
Public Examples from Official Sources
- These examples are sourced from official public Microsoft documentation and sample repositories.
- Documentation examples: https://learn.microsoft.com/azure/ai-services/
- Sample repositories: https://github.com/Azure-Samples?tab=repositories&q=ai&type=&language=&sort=
- Prefer adapting these examples to your tenant, subscriptions, and governance requirements before production use.
Key Takeaways
- Choose models responsibly
- Monitor drift and quality
- Optimize training and deployment